ALL SOLUTIONS
CASE 01 / DOCUMENT INTELLIGENCE
문서를 본문·표·레이아웃까지 한 번에 구조화합니다
HWP부터 PDF·PPT까지, 한국 현장에서 쓰이는 문서 형식을 구분 없이 이해합니다.텍스트·표·이미지·레이아웃을 함께 꺼내어 AI가 바로 활용할 수 있는 구조화된 데이터로 변환합니다.
document-intel.landai.co.kr
PROBLEM
도입 배경 및 검토 과제
01
HWP 등 한국 특화 포맷은 오픈소스 파서 지원이 제한적
02
문서마다 표·이미지·본문이 뒤섞여 구조 추출이 어려움
03
대량 문서를 매일 처리하면서도 정확도·속도를 동시에 확보해야 함
APPROACH
과제 대응 접근 및 기술 아키텍처
01
포맷별 최적 파서 선택
확장자와 내부 서명을 기준으로 HWP·HWPX·PDF·DOCX·PPTX에 각각 최적화된 파서 경로로 라우팅합니다. HWP는 pyhwp 기반, PDF는 pdfplumber 기반으로 레이아웃·표를 함께 추출합니다.
02
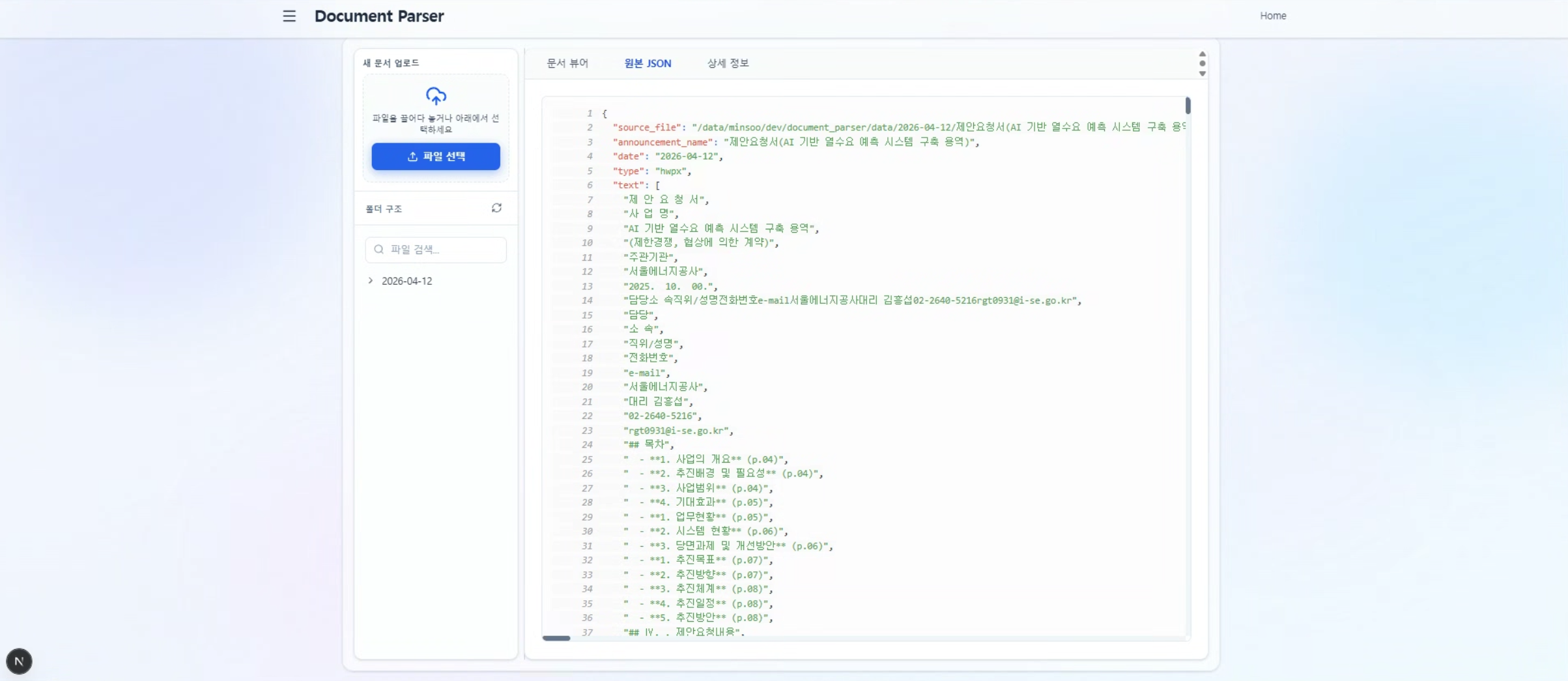
구조 보존형 추출
텍스트·표·이미지·마커를 각각의 자리에서 분리 추출한 뒤, 문단 순서와 레이아웃 정보를 유지한 JSON으로 재구성합니다. 후속 AI 모델이 바로 소비할 수 있는 형태입니다.
03
병렬 · 안정성
2개 이상의 문서는 CPU 코어 기반으로 병렬 처리하고, 한 파일의 실패가 전체 파이프라인을 막지 않도록 설계했습니다. 실패 항목은 통계에 기록됩니다.
04
Human-in-the-Loop
파싱 결과를 원본과 나란히 확인·검토할 수 있는 Next.js 기반 웹 UI를 제공합니다. 검토 상태(pass/fail/pending)와 의견을 함께 관리합니다.
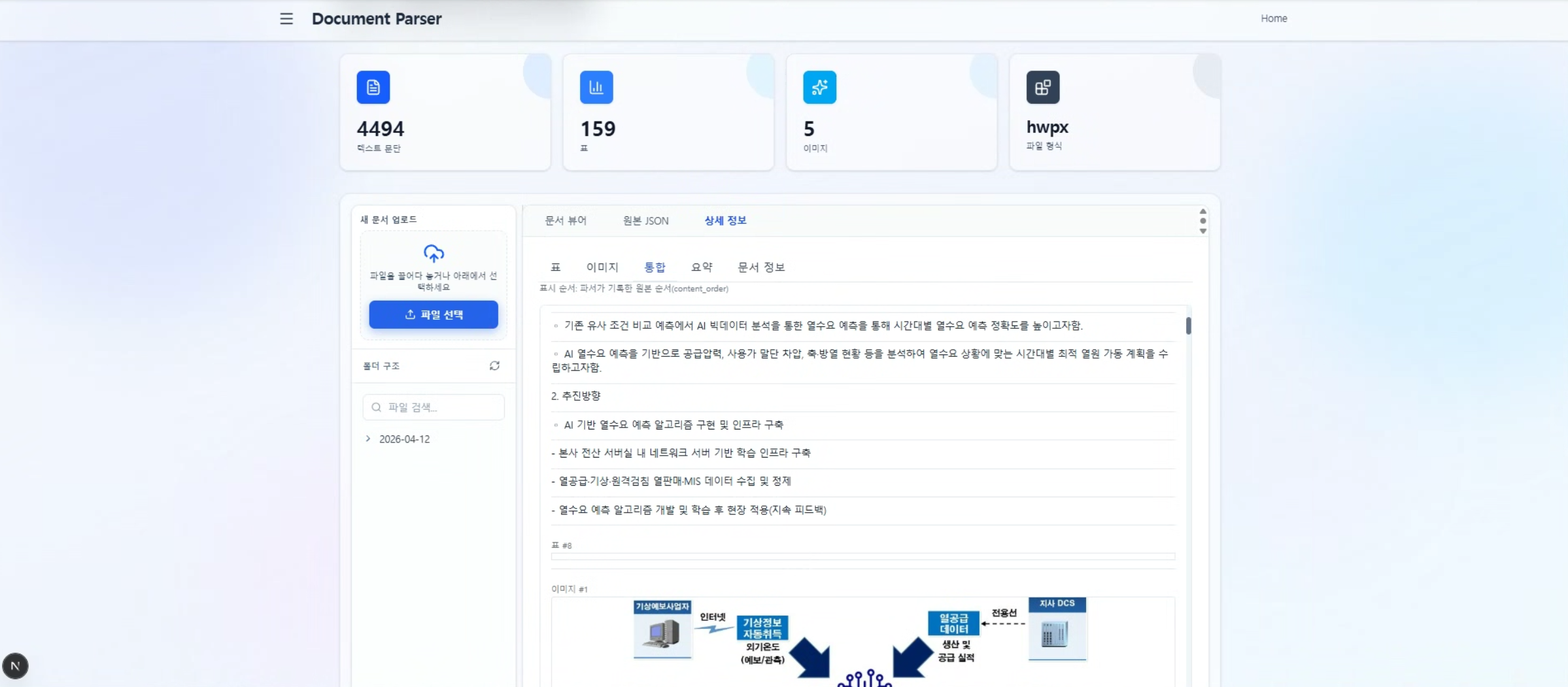
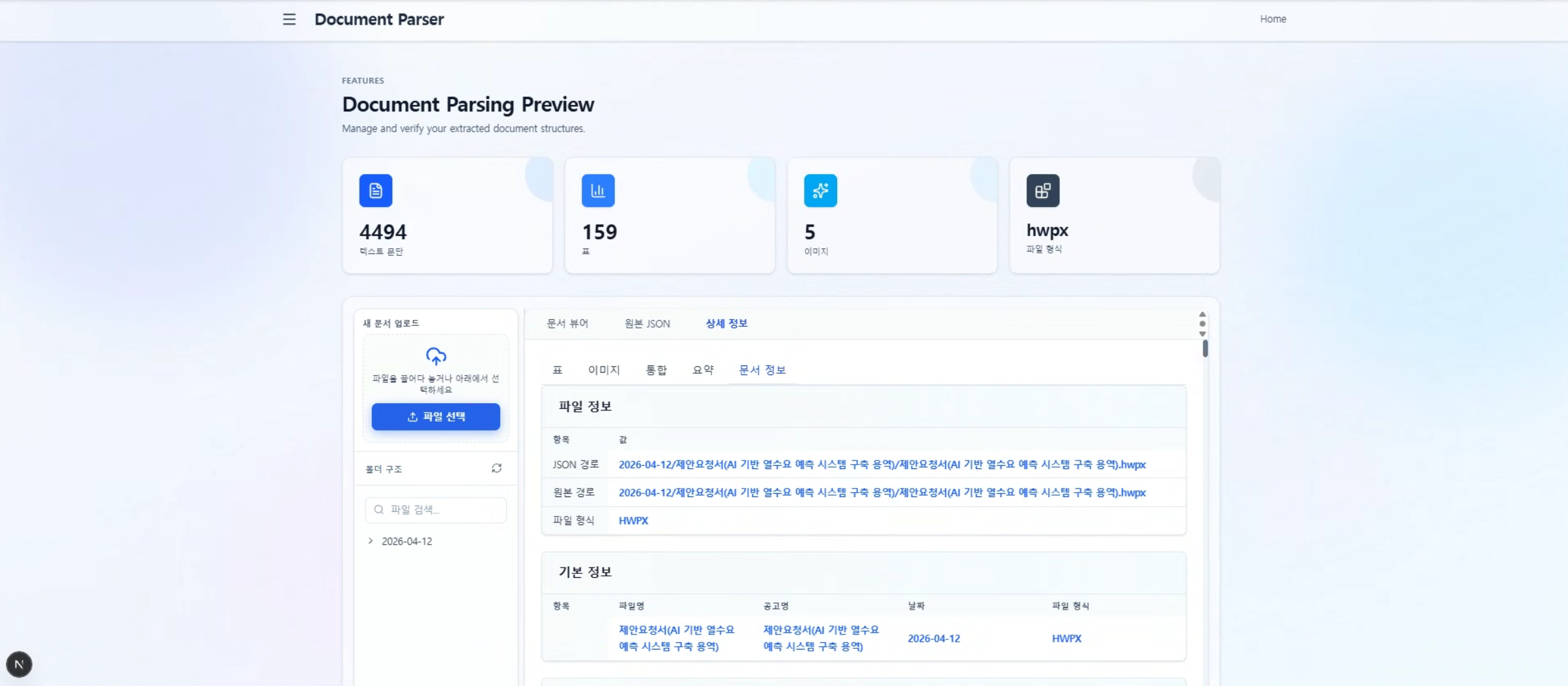
PREVIEW
주요 화면 구성
Human-in-the-Loop 검토 UI와 표·이미지 추출 뷰로, 파싱 결과를 원본과 함께 확인합니다.
human-loop review
extractor · table view
FEATURES
제공 기능 및 지원 범위
- HWP · HWPX · PDF · DOC · DOCX · PPT · PPTX 지원
- 텍스트 · 표 · 이미지 · 레이아웃 동시 추출
- 공고·디렉터리 단위 배치 파싱
- 멀티스레드 병렬 처리 (코어 수 × 2)
- 환경별 설정 분리 (dev / prod / testing)
- 통계 Excel · CSV 자동 생성
- 문서 뷰어 · JSON 뷰어 · 표 뷰어 · 이미지 갤러리
- 파싱 대기·검토 큐 관리